基于TMS320C6201的G.723.1多通道语音编解码的实现
2008/06/03
当前,Voice over IP(VoIP)技术正在不断普及,通过Internet的语音通信量也日渐增加。目前VoIP中使用的低码率语音压缩标准主要有G.723.1和G.729两种。随着VoIP技术的不断发展,要求产品的集成度与性能进一步提高,利用新一代高性能DSP芯片,实现单片DSP处理多路语音信号,是今后的发展趋势。本文根据C6201芯片的特点,作了大量针对G.723.1标准本身的优化,降低了运算量,满足了多路信号的实时实现。
1 G.723.1标准介绍
G.723.1标准是ITU组织于1996年推出的一种低码率编码算法。主要用于对语音及其他多媒体声音信号的压缩,如可视电话系统、数字传输系统和高质语音压缩系统等。
G.723.1标准可在6.3kbps和5.3kbps两种码率下工作。其中,高码率算法具有较高的重建语音质量,而低码率算法的计算复杂度则较低。与一般的低码率语音编码算法一样,G.723.1标准采用线性预测的合成分析法(Analysis-by-Synthesis)。对激励信号进行量化时,高码率算法采用多脉冲最大似然量化(MP-MLQ),而低码率算法则采用算术码本激励线性预测(ACELP)。目前,G.723.1已经能在多种DSP芯片上实现,如美国TI公司的TMS320C5x、TMS320C54x和朗讯科技公司的DSP16xx等。
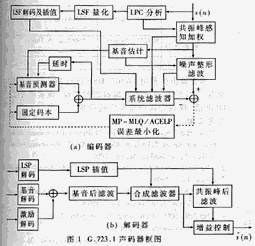
G.723.1编码器能对以8kHz采样的话带语音信号进行压缩,其结构框图见图1(a)。从图中可以看出,编码器是基于线性预测合成分析法原理,其目的是最小化感知加权误差信号。为了降低码率,G.723.1采用了较长的帧尺寸,每帧240个样值,即30毫秒帧长。每帧输入信号首先通过一阶高通滤波器滤除直流分量,然后将之分成四个60个样值的子帧,每个子帧独立进行LPC分析。为了提高LPC系数的连续性,采用了长度为180个样值的重叠窗,即同时包含前后两个子帧,这使算法引入60个样值的超前时延,因此算法的总时延为37.5毫秒。LPC系数用线性谱频率(LSF)表示,LSF参数采用预测分裂矢量量化,只对第四子帧进行。为了提高量化感知质量,高通滤波后的语音信号需通过共振峰感知加权滤波器和谐振峰噪声整形滤波器以生成初始目标信号。前者参数由各子帧的未量化LPC系数构成,后者通过对每两子帧进行开环基音周期估计得到,其中基音周期的范围为18到142个样值。lpc合成滤波器、共振峰感知加权滤波器和谐振峰噪声整形滤波器用于系统零输入响应计算和最佳激励估计。G.723.1编码器还包括一个五阶基音预测器,其参数根据开环基音估计值和脉冲响应进行闭环基音搜寻得到。在进行最佳激励估计时,需从初始目标信号中减去系统零输入响应和基音预测器贡献以得到最终目标信号,然后针对高低码率分别采用MP-MLQ和ACELP方法进行量化。其中LSF参数、基音值和激励参数需传送给解码器。
解码器首先根据得到的LSF参数重建LPC合成滤波器,然后根据基音值和激励参数得到自适应码本激励信号和固定码本激励信号。为了提高重建语音的主观质量,解码器还包括一个后滤波器,后滤波器由共振峰和基音后滤波器组成。激励信号依次通过基音后滤波器、合成滤波器和共振峰后滤波器合成重建语音,其结构框图见图1(b)。
3 标准的实现
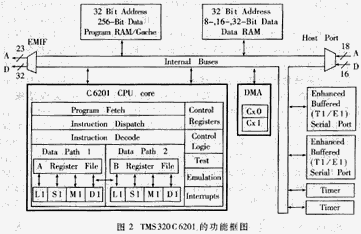
用C6201实现G.723.1标准的最大优势在于它极强的并行处理能力,用一块DSP可以实现多路语音的压缩,大大简化了硬件的设计。C6201是TI公司推出的第一种支持C编译器的DSP芯片。通常,C编译器能完成整个工作的70%,而30%的进一步优化必须通过手写汇编来实现,所以对整个程序的优化分为C语言级和汇编语言级两部分。
3.1 C语言级的优化
3.1.1 循环展开(loop-unrolling)
使用具有并行能力的DSP开发软件时,一个重要的思想就是充分利用DSP的字长和数目众多的运算单元,尽量把循环体展开。通过增加每次循环中执行的指令数来减少总的循环次数,可使得在同样的时钟周期内能运行更多的指令,提高了循环的效率。
3.1.2 提高寄存器的利用率
DSP芯片内部的运算单元运行效率非常高,但如果寄存器和数据总线之间的数据交换频繁,将使DSP的执行效率大打折扣。因为DSP在进行内存操作时,往往需要若干周期的延迟,如Load指令要有4个周期的延迟,STORE指令需要2个周期的延迟。为了减少耗时的内存操作,可以在程序进入循环体之前,将要频繁使用的数据预先放入寄存器,然后反复调用,实践证明这种方法可以提高一部分效率。
3.1.3 使用内在函数(Intrinsic)
内在函数是在某些C6201DSP的汇编指令前加上“_”构成它可以方便地实现某些需若干C语句才能实现的功能。它是一种非常简便高效的优化方法,它的调用格式和普通C函数一样,但在编译时编译器会自动将Intrinsic用对应的汇编指令替代。C6201指令集中绝大多数的运算逻辑指令都可以这样使用,比如饱和绝对值、饱和加、饱和减、饱和乘、两个字中的对应半字同时加或同时减、两个字中的对应半字同时乘或交叉乘、归一化及位操作等。经过此步优化后,大部分循环体都可以生成较为有效的流水内核(piplinedkernel)。用Intrinsic替代G.723.1原先的C代码,运算量下降为原来的1/10。
3.1.4 对算法的冗余部分合理精简
经过检查,发现ITU-TG.723.1的C代码存在冗余部分。象6.3K码率的MP-MLQ搜索模块中,只需要用到偶数位置的脉冲响应的自相关,所以对奇数位置的脉冲响应自相关计算可以省略。
另外,在G.723.1标准中存在大量的10阶FIR和10阶IIR滤波器运算,如编码部分的感知加权、零输入响应、解码部分综合滤波器和后滤波等,FIR和IIR的通用形式可以表示为:
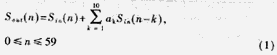
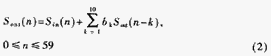
每次循环,FIR滤波器内存要用新的输入值更新,IIR滤波器内存要用新的输出值更新,使用按标准提供的算法,要专门用一个10阶循环更新内存。如果用一个10单位大小的循环缓存区,每次用新值覆盖最老的样值,动态调整循环缓存区的头指针,可以节省原先用于内存更新的cycle。
3.2 汇编级优化
由于C编译器只能完成70%的工作且对于复杂的循环,C编译器无法生成高效率的代码,所以对运算量大的模块只能用手写汇编。
3.2.1 字长优化
C6201的字长为32位,它支持按字节、半字、字存取。对于16位的数组,当它在内存中连续排列时,用32位读写指令LDW或STW替代16位读写指令LDH或STH,循环次数可减少一半。另外,C6201的汇编指令支持两个32位寄存器的高16位和低16位之间互乘,结果分别放到不同的寄存器中,互不影响。具体指令为SMPY(LxL)、SMPYH(HxH)、SMPYHL(HxL)和SMPYLH(LxH)。通过字长优化,可以大大提高程序的运行效率。必须注意的是,在使用字长优化时,数组在内存中的位置必须对齐32位边界。
3.2.2 对外循环的优化
C6201的C编译器对多重循环的最内层一般能较好地优化到一句到两句,但对外循环的优化效率则差很多。手写汇编时,可以先将内循环展开,再把外循环的指令并入其中,可以减少所耗费的cycle数。
C6201的循环一般分前导(Rorlog)、内核(Kernel)及排空(Epilog)三部分。代码的并行程度从Rrolog开始不断提高,Kernel内的并行程度最高,Epilog与Prolog相反,并行性逐渐降低。在多重循环中,如果尽量把内循环前导部分的指令与填入排空部分未用的单元,一起执行,可以在执行本次循环的排空语句的同时执行下次循环的前导语句。这样可不多花cycle而提高整个循环的效率。
4 实现结果
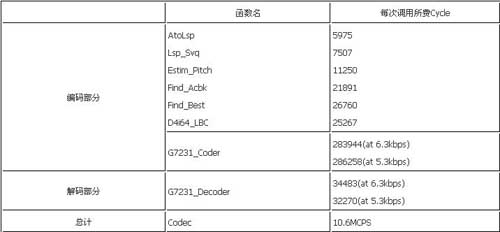
经过C语言级和汇编级的多种优化,最后实现了一路G.723.1的编解码需要花费10.6MCPS,整个代码的程序空间为208K byte(程序中包括了部分c6201的库函数),数据空间为8K byte,码本大小20k byte,多通道的上下文数据为1.48K byte。200MHz的C6201每秒可以实时编解码16路语音信号。所有代码全部通过了ITU-T测试矢量的测试。表1是各主要模块的运算量。
表1 G.723.1各主要模块运算量
本文提出的利用C6201 DSP进行ITU-TG.723.1全双工实时多通道语音编解码的实现。该实现可以在IP电话、视频会议中得到广泛应用。
嵌入式开发网
相关链接: