下一代互联网关键技术IP QoS
姜明 2004/03/15
1.IP QoS产生的背景
互联网源于美国国防部的ARPANET计划。在上世纪60年代中期,正是冷战的高峰,美国国防部希望有一个命令和控制网络能够在核战争的条件下幸免于难,而传统的电路交换的电话网络则显得太脆弱。国防部指定其下属的高级研究计划局(ARPA)解决这个问题,此后诞生的一个新型网络便称为ARPANET。当ARPANET与美国国家科学基金会(NSF)建成的NSFNET互联以后,其上的用户数以指数增长,并且开始与加拿大、欧洲和太平洋地区的网络连接。到了80年代中期,人们开始把互联的网络称为互联网。
早在70年代中期,ARPA为了实现异种网之间的互联与互通,推出了TCP/IP体系结构和协议规范。时至今日,TCP/IP协议也成为最流行的网际互联协议。它不是国际标准化组织制定的,却已成为网际互联事实上的标准,并由单纯的TCP/IP协议发展成为一系列以IP为基础的TCP/IP协议簇。TCP/IP协议簇为互联网提供了基本的通信机制。
随着互联网的指数增长,其体系结构也由ARPANET基于集中控制模型的网络体系结构演变为由ISP运营的分散的基于自治系统(Autonomous
systems AS)模型的体系结构。互联网目前几乎覆盖了全球的每一个角落,其飞速发展充分说明了TCP/IP协议取得了巨大的成功。
但是互联网发展的速度和规模,也远远出乎于二十多年前互联网的先驱们制定TCP/IP协议时的意料之外,他们从未想过互联网会发展到如此的规模,并且仍在飞速增长。随着互联网的普及,网络同人们的生活和工作已经密切相关。同时伴随互联网用户数膨胀所出现的问题也越来越严重。除了我们众所周知的IP地址匮乏外,另外一个严重问题就是缺乏服务质量(Quality
of Service QoS)保障。
现有的互联网所提供的是"尽力而为"(best-effort)的服务,在这种服务模型下,所有的业务流被"一视同仁"地公平地竞争网络资源,路由器对所有的IP包都采用先来先处理(First
Come First Service FCFS)的工作方式,它尽最大努力将IP包送达目的地。但对IP包传递地可靠性、延迟等不能提供任何保证。这很适合Email、Ftp、WWW等业务。
但随着互联网的高速增长,IP业务也得到了快速增长和多样化。特别是随着多媒体业务的兴起,计算机已经不是单纯的处理数据的工具,而是越来越贴近生活,计算机的交互越来越实时和生动,这对计算机互联网络也就相应地提出了更高的要求。对那些有带宽、延迟、延迟抖动等特殊要求的应用来说,现有的"尽力而为"的服务显然是不够的。尽管由于网络技术的发展,网络带宽以及网络速度都得到了极大的提高,但需要通过网络传输的数据却也几乎以与网络发展速度相同的速度增加,甚至超过网络发展的速度,这使得网络带宽与网络速度依然是一个瓶颈问题。同时,近年来发展起来的一些新的应用(如多媒体应用,组播应用等)不仅增加了网络流量,更因为这些应用改变了以往互联网上的流量性质,因而它们需要全新的服务要求。由于不具备服务质量保障特性,不能预留带宽,不能限定网络时延,因此,目前的因特网无法支持许多新的应用如远程教学、远程手术、远程会议和学术交流等。
2.IP QoS的定义及其实施方案
IP QoS的研究目标是有效地为用户提供端到端的服务质量控制或保证。QoS就是网络单元(例如,应用程序,主机或路由器)能够在一定级别上确保它的业务流和服务要求得到满足。QoS并没有创造带宽,只是根据应用程序的需求以及网络状况来管理带宽。IP
QoS有一套性能参数,主要包括:
业务可用性:用户到Internet业务之间连接的可靠性。
传输延迟:指两个参照点之间发送和接收数据包的时间间隔。
可变延迟:也称为延迟抖动(Jitter),指在同一条路由上发送的一组数据流中数据包之间的时间差异。
吞吐量:网络中发送数据包的速率,可用平均速率或峰值速率表示。
丢包率:在网络中传输数据包时丢弃数据包的最高比率。数据包丢失一般是由网络拥塞引起的。
实现QoS的一种方法是按照服务水平的要求分配资源给每一个数据流。这种采用"资源预留"进行带宽分配的方法并不适合"尽力而为"型应用。由于带宽资源是有限的,QoS的设计者引入了优先级概念,使得在资源预留后"尽力而为"服务的数据流的传输也能得到一定的保障。因此,IP
QoS可以分为两种基本类型:
基于资源预留:网络资源按照某个业务的QoS要求进行分配,制定资源管理策略。互联网工程任务组IETF(Internet Engineering
Task Force)提出的综合服务(Integrated Services, IntServ)体系结构便是基于这种策略,资源预留协议(Resource
reSerVation Protocol, RSVP)是其核心部分。
基于优先级:网络边界节点对业务流进行分类、整形、标记。核心节点按照资源管理策略分配资源,对QoS要求高的业务给以优先处理。IETF提出的区分服务(Differentiated
Services,DiffServ)便是基于这种策略。
这些QoS方法可以被用于单个数据流或聚集的数据流(aggregate flow)。根据应用的数据流的不同,IPQoS可以分类为:
用于单数据流:单个数据流为在两个应用(发送者和接受者)之间的单个的、单向的数据流。可以用传输协议、源地址、源端口号码、目的地址和目的端口号码这五种参数来分类。
用于聚集流:综合流由两个或更多个单个数据流组成。这些流在一个或多个参数、标记或优先数以及一些认证信息方面有一些共同点。
为了解决IP QoS问题,IETF已经提出了几种服务模型和机制,主要有:
综合服务和资源预留协议IntServ/RSVP:以RSVP信令向网络提出业务流传输规格(Flowspec),并建立和拆除传输路径上的业务流状态。主机和路由器节点建立和保持业务流状态信息。尽管RSVP经常用于单个流,但也用于聚流的资源预留。
区分服务:在区分服务网络中,边界路由器根据用户的流规格(stream profile)将用户流划分为不同的级别,再聚合成流聚集,聚集信息存放在IP包头的DS标记域,称为DS标记(Differentiated
Services CodePoint,DSCP)。内部节点则根据DSCP提供不同质量的调度转发服务。
多协议标记交换(MultiProtocol Lable Switch,MPLS):根据分组头的标记,通过网络路径控制来提供流聚集的带宽管理子网带宽管理(Subnet
Bandwidth Management,SBM):负责OSI第二层(数据链路层)的分类和优先级排列,同IEEE 802网络进行共享和交换。
3.综合服务模型和资源预留协议
IntServ/RSVP简介
Int-Serv/RSVP服务模型在IETF RFC1633中进行了定义。RFC1633将资源预留协议RSVP作为IntServ结构中的主要信令协议。其基本思想就在于以资源预留的方式来实现QoS保障,RSVP是其核心部分。RSVP是主机用来从应用程序获得特定的QoS的一种控制协议,完成综合服务需要定义的呼叫接纳控制功能和资源预留功能。端点应用程序利用RSVP消息向网络提出完成数据传送必须保留的网络资源(如带宽及缓冲区大小等),同时也确定沿传送路径的各个节点传输处理策略,从而对每个业务流实现逐个控制。
在服务层次上,IntServ/RSVP提供了3种级别的业务:
端到端的质量保证型服务(Guaranteed Service):保证带宽、限制延迟、无丢包。
可控负载型服务(Controlled-Load Service):类似于在当前的一个负载较轻网络中实现的尽力而为业务的服务质量。
尽力而为的服务(Best Effort Service):类似当前Internet在提供的尽力而为的服务。
在结构层次上,IntServ/RSVP服务模型主要由四个部分构成:信令协议RSVP,接入控制器(admission control routines),分类器(classifier)以及包调度器(packet
scheduler)。
在实现层次上,综合服务需要所有路由器在控制路径上处理每个流的信令消息并维护每个流的路径状态和资源预留状态,在数据路径上执行流的分类、调度和缓冲区管理。具体而言,资源预留协议RSVP负责逐点(hop-by-hop)地建立或者拆除每个流的资源预留软状态(soft
state),也即建立或拆除数据传输路径;接入控制器将决定是否接受一个资源预留请求,其根据是链路和网络节点的资源使用情况以及QoS请求的具体要求;分类器则对传输的数据包进行分类成传输流,
IntServ常用的分类器是多域(Multi-Field,MF)分类器,当路由器接收到数据包时,它根据数据包头部的多个域(如5元组:源IP地址,目的IP地址,源端口号,目的端口号,传输协议),将数据包放入相应的队列中;调度器则根据不同的策略对各个队列中的数据包进行调度转发。
资源预留协议RSVP
RSVP早在1993年就被提出,用于为IP网提供QoS能力。1997年初IETF批准RSVP成为RFC文件,在+IntServ工作组内进行标准制定工作。RSVP是一种提供预留设置和控制以实现综合服务合协议,是所有QoS协议中最复杂的。RSVP资源预留请求包括流规格说明(TSpec)、资源预留规格说明(RSpec)和过滤器规格说明(Filter
Spec),它们一起称为"流描述符"(Flow Des-criptor)。资源预留请求中的流规格说明通常包含服务类型和数字参数集合。预留说明和业务流说明决定于综合服务模型并且对RSVP来说是透明的。过滤器规格说明的格式依赖于所使用的网络层协议,即IPv4或IPv6。目前所用的RSVP中定义的基本过滤器规格说明格式具有严格的形式:发送端IP地址和可选的TCP/UDP端口号。在服务保证、资源分配的粒度和对保证QoS应用及用户反馈的细节等方面RSVP都能提供最高级的QoS。归纳起来,RSVP有以下6个特点:
在每一个路由器中的预留是"软"的,这意味着需要由接收者周期地更新。
RSVP不是传输协议而是网络(控制)协议,它不携带数据,但是和TCP或UDP数据流并行工作。
应用要求API决定流的初始预留请求,并且接收在经过初始请求和全过程中预留成功或失败的通知。
为了能够容纳大量不同的接收者,预留是以接收端驱动的(Receiver-Driven)。
多播的预留在上行的数据流复制点上被结合。
RSVP数据流可以通过不支持RSVP的路由器,这会在QoS链上产生弱链路,在这些弱链路上无法提供QoS保证,因而此时的服务就是尽力而为型的。
使用RSVP信令建立数据发送路径以及为业务流预留资源的过程如下:
发送端向接收端发送一个包含业务流规格说明(TSpec)的PATH消息,其中包含了业务流标识(即目的地址)及其业务特征,包括所需要的带宽的上下限,延迟以及延迟抖动等。如图1中①所示。
该消息由沿路径的路由器逐跳传送,并且每个路由器都被告知准备预留资源,从而建立一个"路径状态",该状态信息包含PATH消息中的前一跳源地址。如图1中②、③所示。
接收方收到此消息后从业务特征和所要求的QoS计算出所需要的资源,向其上游节点发送一个资源预留请求RESV消息,该消息中包含了TSpec、RSpec以及Filter
Spec,其主要包含的参数就是要求预留的带宽。如图1中④所示。
RESV是沿PATH的发送路径原路返回的,沿途的路由器收到RESV消息后,调用自己的接入控制程序以决定是否接受该业务流,如果接受,则按要求为业务流分配带宽和缓存空间,并记录该流状态信息,然后将RESV消息继续向上游转发;如果拒绝,则向接收端返回一个错误信息给接收端以终止呼叫。如图1中⑤所示。
当最后的路由器收到RESV消息并且接受该请求时,它向接收端发回一个确认消息。如图1中⑥所示。
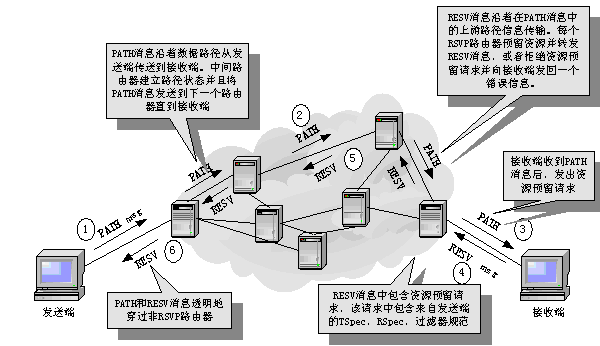
图1 RSVP建立传输路径以及预留资源的过程
在此过程中,我们注意到,和电信网络中的呼叫建立过程相反,RSVP是由接收端驱动的资源预留。其目的是考虑在组播的情况下,以接收端驱动,可以适应组播群成员的动态增减,以及各接收端要求不同QoS的异质请求情况。当通信结束或者一方退出会话后预留的资源可以由超时机制释放。RSVP还定义了显式的释放机制,通过PathTear由启动点沿下游方向传送至接收端,通知沿途各路由器释放资源。ResvTear则反向传送,功能相似。它们可由端系统发出,也可由路由器在状态超时时发送出。至此,业务流的传输路径已经建立起来了,数据流可以进行发送了。
RSVP可以看作是配置业务处理的机制,综合服务则是在RSVP信令基础上够用以提供端到端QoS保证的体系结构。IntServ设定网络设备支持业务的处理机制,保证每一个业务流严格独立于其他业务流的服务,并设定提供特定量化资源的服务。
从以上讨论可以看出,IntServ/RSVP服务模型对传统Internet体系结构的扩展主要包括在路由器中保存业务流状态信息以及明确的状态建立机制。这种模型在路由器中所保存的业务流状态信息是软状态信息,由于软状态信息在路由器发生错误时容易通过RSVP信令刷新而隐含地拆除并在另外路由器中重建业务流状态信息,而硬状态信息(hard
state)需要明确地拆除状态信息,因而保持了网络体系结构的鲁棒性(robustness)。同时,由于这种模型有效地集成了各种实时应用和非实时应用,因而保持了网络的效率。另外,由于兼容了传统网络体系结构和协议栈,因此能对网络进行有效的管理。
IntServ/RSVP的缺陷
从理论上讲IntServ/RSVP模型完全可以保证为IP网络提供QoS保障。但随后在一些网上的实验表明这种服务模型有很明显的局限性,这些问题主要表现在:这不仅表现在扩展性差上,更大的问题是它要求核心路由器必须保持经过它的每一个单个数据流的状态,而核心路由器是不能这么做的。另一个大问题是这种方法因此,尽管主要的路由器生产商和主机都支持RSVP,它也被广泛接受,但是它始终没有成为主流,原因是ISP们不愿意采用它,很少有大型网络采用它。近来,人们认识到RSVP的出路在于与区分服务配合工作,相辅相成。
可扩展性差:可扩展性是IntServ/RSVP模型最致命的一个问题,其基于流的资源预留、调度处理以及缓冲区管理,有利于提供QoS保证,但状态信息随业务流数量的增长而增长,沿途的路由器要为每个数据流都维持一个"软状态",而路由器的存储器容量有限,可以保存的软状态信息都是有限的,在一个运营商规模的网络中几乎不可能实现这一要求。
对路由器的要求过高,网络中所有的路由器都必须支持RSVP信令协议,接入控制程序,分类器以及调度器。
RSVP中引入每流状态(per-flow state)的概念,对于数据通信和实时应用通信而言,IP网络同时扮演了面向无连接和面向连接网络的两个不同角色,提供两种功能,这与其简化设计原则相抵触。
资源预留不适用于短时流,比如Web流等,而在因特网中Web流量超过了50%。
IntServ/RSVP还存在着资源预留和路由协议之间的矛盾。如图2所示,从路由角度来看它是一条好的路径,但从资源预留来看,由于没有足够的资源可以预留,不能为数据流建立起一条路径,因此这一进程只能停留在这里,等待上层超时拆除这个应用进程,再重新建立路径。
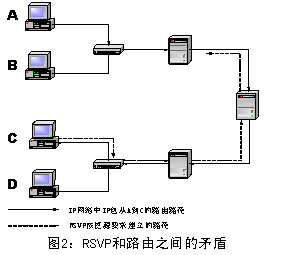
因此,要实现IntServ的QoS保证是很困难的,它需要基于流的、复杂的资源预留、接纳控制、QoS路由和调度机制。在诸如互联网这种复杂的、大规模的网络中,链路状态是不确定的,有效地预留带宽资源非常困难。而且资源预留本身就与IP网络的最大特点"无连接"相冲突。更重要地问题就是IntServ面临地可扩展性(scalability)问题和鲁棒性(rubustness)问题,这主要是因为在分布式网络环境中,很难维持动态的、可复制的传输流状态一致性。
早期的IntServ是面向单流的,在路由器配置和使用多域分类准则,这给路由器尤其是主干网络核心路由器带来了巨大负荷。为了增加IntServ的扩展性,近期RSVP已经开始支持流聚集,即将沿相同业务流传输路径流聚合成宏流(macro-flow),按宏流来预留资源。这虽然减轻了核心路由器的一些负担,但IntServ本身的体系结构已经决定了其高复杂性,而且由于路径数是边界节点数的平方,宏流数仍然很庞大。
由于IntServ/RSVP体系存在着诸多问题,一种新的体系结构便应运而生,这就是区分服务体系结构(Differentiated Services,DiffServ)。
4.区分服务
区分服务简介
DiffServ的最大特点就是简单有效、扩展性强。其实施特点是采用聚合的机制将具有相同特性的若干业务流聚合起来,为整个聚合流提供服务,而不再面向单个业务流。也就是说在DiffServ网络边界路由器上保持每流状态,核心路由器只负责数据包的转发而不保持状态信息。这种Core-Stateless结构有很强的扩展性。其基本实现方法是:
简化网络内部节点的服务机制。在网络内部的核心路由器中只保存简单的DSCP(DiffServ CodePoint)与PHB的对应机制,在数据流进入核心路由器时只根据数据包头部DS(Differ-
entiated Services)域中的DSCP进行转发,而业务流状态信息的保存与流监控机制的实现等都在网络边界节点进行,内部节点是状态无关的。
聚合网络内部核心路由器的服务对象。采用流聚集的方式进行传输控制,具有相同DSCP的业务流组成一个宏流(macro-flow),核心路由器的服务对象即是宏流而不是单流(micro-flow),单流信息只在网络边界节点保存和处理。
DiffServ大大降低了信令的工作,而将重点放在流聚集以及适用于全网业务等级的一套"逐跳行为"上。我们可以根据预先确定的规则对数据流进行分类,从而将多种应用数据流聚集为有限的几种数据流等级。具体而言,边界节点根据用户的流规格(profile)和资源预留信息对业务流进行分类、整形、标记、聚合为不同的流聚集,流聚集信息包含在报文IP头部的DSCP标记域中。核心路由器在调度转发IP包时以流聚集为服务对象,根据IP包头不同的DSCP提供不同的转发服务质量,这种对不同类型的数据报进行转发的方式,称为"逐跳行为"(Per-Hop-Behavior,PHB),实际上是一种相对优先级机制。
实际上,按照DS域的标记,以相应方式提供不同质量的数据包转发服务,也正是区分服务名字的由来。美国正在开展的下一代互联网计划Internet2便是选择DiffServ作为其QoS策略。
区分服务的体系结构
虽然DiffServ仍在不断的发展,一些标准仍在制定、完善之中,但经过几年的发展,DiffServ的相关概念及模型已经比较成熟了,DiffServ体系结构也已经比较明确了。在此基础上,与服务提供有关的问题,如DSCP的定义、PHB服务的定义等等已逐步完善。区分服务体系结构如图3所示。
其中的DiffServ区域是由一些相连的DiffServ节点构成的集合,它们有统一的服务提供策略,且实现一致的PHB组,比如某个ISP的网络或者内部网。每个DS区域通过边界节点(boundary
node)与非DS区域相连,根据不同的数据流传输方向,边界节点可以分为入口节点和出口节点。
为了保证用户能从ISP那里获得所需要的服务质量,用户必须和ISP之间签订有服务等级协定(Service Level Agreement, SLA),而ISP之间也必须建立业务流调节协定(Traffic
Condition Agreement, TCA),SLA规范了ISP对客户端网络所支持的业务类别以及每种类别的业务流数量,TCA则规范了ISP之间的数据流应该满足的一些约定。
这样,当有数据流进入DS区域时,入口节点对其进行分类(classifier)、调节(condition),保存流(单流或聚流)的状态信息,根据事先和用户约定的流规格对流进行计量(metering)、标记(marking)、整形(sharping)、丢弃(dropping)等,以使输入流符合SLA,同时在包头标记DSCP值,并将其加入相应的行为聚集BA(Behavior
Aggregate)。出口节点也可能需要对输出流进行调节,以保证其与下游DS区域的TCA相符。
DiffServ区(region)则是由连续的DS区域构成。一个DS区内的DS区域可以支持不同的PHB组,并且各自区域的DSCP到PHB的映射函数也可能不相同。在不同的DS区域之间,必须对SLA和TCA进行调节,以协调彼此之间的服务语义。这样,通过在上游DS区域和下游DS区域之间建立SLA或TCA,区分服务可以扩展到多个DS区域。
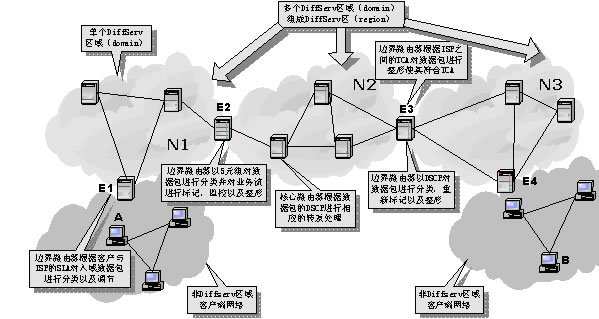
图3 区分服务体系结构示意图
在图3中,我们假设客户端网络已经和ISP建立了相应的SLA,ISP之间也建立了TCA。如果客户端网络中的主机A向另一客户端网络的主机B发送数据流,则数据包在客户端网络中路由到达与它直接相连的ISP的网络N1,边界路由器E1根据用户与ISP之间的SLA通过查看数据包的头部信息对它进行分类、监控、标记以及整形,以使它符合SLA。被标记了DSCP的数据包在N1中传输,直到到达N1的出口节点。在N1的出口节点,边界路由器根据N1与N2之间的TCA对业务流进行整形,使它符合N1与N2网络之间的TCA。业务流依次通过中间的每个ISP,最后到达接收端所在的客户端网络。
区分服务标记域与区分服务标记DSCP
IP包头部的区分服务标记域(DS Field)是DS区域边界节点和内部节点传输流聚集信息的媒介,是内部核心路由器转发报文的依据,是连接报文与转发服务(PHB)的桥梁,也是边界节点与其它DS区域根据TCA进行调节的依据。
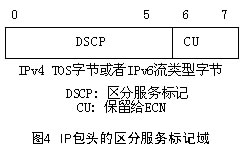
DS标记域定义为IPv4头部的TOS(Type of Service)字节或IPv6头部的流类型(Traffic Class)字节。如图4所示。其中DSCP(6bit)即为区分服务标记,CU(2bit)在本体系中没有使用,IETF已将它定义为ECN(Explicit
Congestion Notification,显式拥塞指示)使用。对于不支持CU域的路由器,当决定所收到的报文的PHB时,将忽略CU的值;对于不支持该域的主机,在发送数据包的时候,将该域的值置零。下行节点则通过识别这个字段,获取信息来处理到达输入端口的数据包,并将它们正确地转发给下一跳的路由器。
分服务中的分类和调节机制
为了使用户数据流符合SLA和TCA,边界节点要对其进行分类和调节,因而从功能上可以分为两个模块:分类器(classifier)和调节器(conditioner),如图5所示。
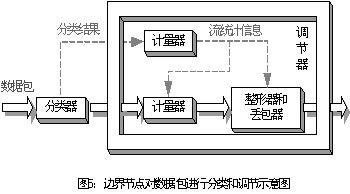
分类器根据数据包头部的某些域(如DSCP或MF五元组)对数据包进行分类。目前定义了两种类型的分类器:
行为聚集(Behavior Aggregate,BA)分类器:根据包头的DSCP来对包进行分类。
多域(Multi-Field,MF)分类器:根据包头部中多个域内容的组合来进行分类,如源地址、目标地址、DS域、协议标识、源端口号以及目标端口号等。
从功能上,调节器可分为计量器(meter)、标记器(marker)、整形器(sharper)和丢包器(dropper)。
计量器根据TCA中所规范的业务流要求测量被分类器所选定的业务流的某些实时属性,并将所测量到的数据包的统计信息送往其它的调节功能模块。
标记器设置报文的DS域为一特定的DSCP,并将标记了的包添加到一特定的DS行为聚集中。标记器可以将所有送入到它那儿的包标记为同一个DSCP值,也可以配置成根据计量器的统计信息将其标记为同一PHB组内的PHB所对应的DSCP值。
整形器和丢包器则通过延迟或丢弃业务流中的包使得业务流符合TCA流规范。
随着对网络业务流特性研究的深入发展,调节器的实现技术也日渐成熟,通常的做法是用令牌桶(token bucket)和漏斗桶(leaky bucket)等算法进行适当的组合。近来又提出了一种新的算法:基于时间滑动窗口(Time
Slide Windows,TSW)的算法,它是通过计算数据包的平均到来速度来对包进行分类和标记。
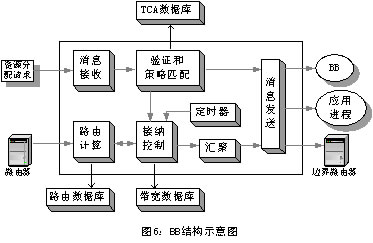
在客户端网络与ISP建立的SLA有两种形式:静态SLA和动态SLA。静态SLA根据具体的策略由网络操作员事先确定客户网络所需要的网络资源,并一直为客户端网络保留相应的资源,这样,客户端网络在发送数据流的时候,并不需要向ISP申请网络资源。显然,这种SLA实现简单,但缺乏灵活性,网络资源利用率不高。动态SLA则相反,它提供了较强的灵活性。当客户网络需要发送数据时,它首先向ISP申请网络资源,ISP根据客户请求分配资源,并在边界节点建立起相应的SLA。动态SLA可以使用带宽代理(Bandwidth
Broker, BB)(如图6)或者RSVP来实现
区分服务中的逐跳行为
逐跳行为PHB是一个DS节点调度转发特定流聚集行为的外特性描述,本质上,PHB描述的是单个节点为特定流聚集分配资源的方式。IETF目前已经定义的PHB有:
加速型转发(Expedited Forwarding,EF):可使时延和时延抖动最小并且可以提供最高级的综合QoS确保型转发(Assured
Forwarding,AF):超过流量规划值的数据流,不会按照未超过规划值时那么高的概率传送。这意味着它可以被降级,但是不会被丢弃。
允许丢包的加速型转发EFD:除了EFD允许丢包而EF几乎没有丢包外,EFD与EF的外特性几乎相同。EFD的应用主要是在无线移动网络中。
缺省型转发 BE:相当于传统的极力而为调度转发行为的PHB。
准缺省型转发 LBE:比BE优先级还要低的PHB行为,其作用是在拥塞时有比BE更高的丢包优先级,提高BE的性能。
区分服务的基本服务类型
与IntServ类似,Diff-Serv也定义了三种服务类型:
尽力而为的服务:类似于目前Internet上尽力而为的服务。
奖赏服务(Premium Services,PS):为用户提供低延迟、低抖动、低丢包率和保证带宽的端到端或者网络边界到边界的传输服务。PS是目前区分服务模型中定义的级别最高的服务种类。这种"三低一保证"的服务类似于传统运营商网络的专线业务,因此也称为"虚拟专线"服务。
确保服务(Assured Services,AS):确保服务是从统计上保证用户的带宽,其初衷是在网络拥塞的情况下,也能保证用户有一定量的预约带宽。AS的着眼点是带宽和丢包率,而不太注重延迟和抖动。AS最具吸引力的是其实现机制较为简单,只要采用简单的标记和丢弃机制就能实现IP
QoS。在发生拥塞时,确保服务通过控制丢包优先级,提供了比"尽力而为"服务更好的服务。确保服务的基本思路是:
边界路由器对进入DS域的数据包进行标记,预约带宽内的包标为IN(in profile),否则标为OUT(out profile)。
发生拥塞时,核心路由器根据包头的标记决定丢包概率,Out包的丢弃概率大于In包。从而在统计意义上上保证用户的预约带宽。
目前,奖赏服务已经比较成熟、稳定,而确保服务仍然处于发展之中,其焦点主要集中在如何保证聚流之间的个公平性以及聚流内各单流之间的公平性,这主要是由于Internet上数据流的特性引起的。研究表明,现有的确保服务方案并不能真正确保用户得到的服务,因此,如何使得确保服务能够真正起到确保的作用,还有待进一步研究。
5.多协议标签交换MPLS
1997年,以Cisco公司为主的几家公司(包括Ipsilon、IBM、Cascade、Toshiba)提出了多协议标签交换(Multiprotocol
Lable Switch,MPLS)技术。MPLS技术产生的初衷就是为了综合利用网络核心的交换技术和网络边缘的IP路由技术各自的优点而产生的其最初设计目标是将第二层的交换速度引入到第三层。基于标签的交换方式允许路由器在作转发决定的时候仅仅以简单的标签为基础,而不是基于目标IP地址作复杂的路由查找。现在,MPLS更成为流量工程(Traffic
Engeering)和虚拟专用网(Virtual Private Network,VPN)方案的重要解决手段,并且日益成为扩大IP网络规模的重要标准。
MPLS中的常用的术语
标签(Label):标签是一个包含在每个包中的短的具有固定长度的数值,用于通过网络转发包。
标签边缘路由器(Lable Edge Router,LER):LER是MPLS网络同其他网络相连的边缘设备,它提供流量分类和标签的映射(作为Ingress)、标签的移除功能。
标签交换路由器(Lable Switching Router,LSR):LSR是MPLS网络的核心设备,提供标签交换、标签分发功能,具有第三层转发分组和第二层交换分组的能力。
等价转发类(Forwarding Equivalence Class,FEC):FEC是在转发过程中以等效的方式处理的一组数据包,例如目的地址前缀相同的数据包。FEC归类的方法可以各不相同,粒度也可有差别。
标签交换路径(Lable Switching Path,LSP):MPLS实际上是一个面向连接的系统,标签的分配实际上就是一个建立连接的过程,也即建立了一条LSP。LSP可以是动态的,也可以是静态的,动态LSP是通过路由信息自动生成,静态LSP是被明确提供的。
标签分配协议(Label Distribution Protocol,LDP):LDP提供一套标准的信令机制用于有效地实现标签的分配与转发功能。LDP基于原有的网络层路由协议OSPF、IS-IS、RIP、EIGRP或BGP等构建标签信息库,并根据网络拓扑结构,在MPLS域边缘节点(即入节点与出节点)之间建立LSP。LDP主要执行以下4个操作:
发现(Discovery):发布并维护网络中的LSR。
会晤(Session):建立和保持两个对等LDP之间的会晤。
广告( Advertisement):执行标签的分配和传播( allocation and distribution)。通知(Notification):通告差错信息。
MPLS的基本原理
MPLS协议的关键是引入了标签(Label)的概念。一对LSR必须在标签的数值和意义上一致。例如,下行LSR会给上行LSR发送一个特定标签X.代表一个特定的称作A的FEC。于是,一个标签只在一对正在通信的LSR之间起作用,并用来表示属于一个从上行LSR流向下行LSR的特定FEC的分组。MPLS可以支持添加到现有的帧或分组结构(如以太网、PPP)的标签,也可以利用包含在数据链路层(如帧中继和ATM)中的标签结构。
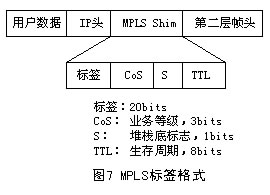
标签的格式取决于分组封装所在的介质。例如,ATM封装的分组(信元)采用VPI和/或VCI数值作为标签,而帧中继PDU采用DLCI作为标签。对于那些没有内在标签结构的介质封装,则采用一个特殊的数值填充。图7给出4字节填充标签的格式,它包含一个20bits的标签值、一个3bits的CoS值、一个1bit的堆栈标识符和一个8bits的TTL值。此外.如果填充值被插入到一个PPP或以太网帧中,包含在各帧头中的一个协议ID(或以太网类型)表示一个帧或者一个
MPLS单播或组播帧。
传统的路由器是通过逐步查找路由/转发表来转发数据的(hop by hop路由方式),由于路由查找基本上是通过CPU来完成的,所以转发速率受到很大的限制,这种转发效率远远不能满足目前互联网的发展需要,尤其是一些高带宽和对时延敏感的多媒体业务大量进入互联网后。而MPLS的一个根本目的就是解决转发速率问题。其方法就是依据标签这个短小、定长、非结构化并只具有局部意义的标识来转发分组。由于标签的这些特点,所以标签的查找可以采用数组来实现,无论是用硬件还是用软件来实现都不难。
当一个数据包进入MPLS网络时,它首先在LER处被分配一个标签。报文沿着LSP进行转发,路径中的每个LSR仅仅根据标签内容来做出转发决定。在每一跳中,LSR剥离现有的标签,将一个新的标签应用于该报文,并告诉下一跳如何转发该报文。
具体而言,每个进入MPLS网络的数据包被归类为一个转发等价类(Forwarding Equivalence Class, FEC),该等价类以一个标签来标识,因此,报文中的标签内容也就表示了该报文所分配的FEC。传统的路由器在进行包转发时,各个路由器是独立地作出转发决定的,也就是说,每个路由器都将查看包头的目的地址,而在MPLS中,只是在报文进入MPLS网络的LER时查看包的目的地址,在其它路由器并不查看包的目的地址,而仅仅根据其标签内容来作出转发决定。在数据包进入到LSR时,入域标签映射(Incoming
Label Map, ILM)机制将入域包的标签内容与一组下一跳标签转发入口(The Next Hop Label Forwarding Entry,NHLFE)相映射。LSR查看该NHLFE,决定向哪个接口转发该包,并对包的标签栈执行一个操作,然后将新的标签压入标签栈,转发所得到的结果。
MPLS在流量工程中的应用
流量工程(Traffic Engineering,TE)的主要目的就是在促进有效、可靠的网络操作的同时,优化网络资源的利用率和流量的性能。一般来说,它包含了技术的应用、测量的科学准则、模型化、特征化(Characterization)和因特网流量的控制,以及如何将这些知识和技术应用到实践中来获取一些特定的性能指标。由于网络资源的昂贵和因特网激烈的商业竞争的天性,流量工程已经成为大型自治系统(Autonomous
System,AS)中一个不可缺少的功能。
MPLS的最初设计目标是将第二层的交换速度引入到第三层,随着第三层交换速度的大大提高,这一最初目标已经不复存在了,而现在MPLS的最主要功能就是流量工程,即在多条可能的转发路径中进行负载平衡。
流量工程是指为业务流选择路径的处理过程,以在网络中不同的链路、路由器和交换机之间平衡业务流负载。当网络中存在多条并行或可选的路径时,流量工程就显得非常重要了。流量工程的主要目的是提供有效可靠的网络操作,同时优化网络资源的利用和业务流性能。流量工程的目标是在一给定节点与另一节点之间计算一条路径(源路由),该路径不违反它的约束(例如带宽/管理要求),并且从一些数量指标看来是最优的。一旦路径被计算后,流量工程将负责在该路径上建立和维护转发状态。
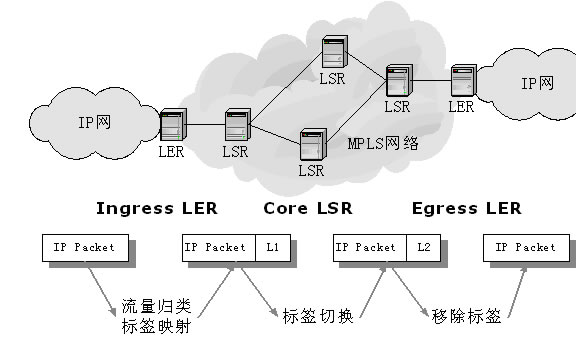
图8 MPLS体系结构
6.子网带宽管理SBM
由于数据包的发送过程必须经过发送端主机以及接收端主机的所有OSI协议层,甚至可能要经过中间某个网络的子网。这就涉及到一个问题:如何在子网内,即在数据链路层上保证高优先级的数据帧获得高级别的服务。某些链路层的技术已经可以支持QoS了,例如异步传输模式ATM。而其它更多的LAN技术(如以太网技术)最初并非为支持QoS设计的。以太网作为共享的广播媒介,在它的交换方式中,提供了一种类似与传统的尽力而为的IP服务。为此,IETF的ISSLL小组定义了上层QoS协议和服务与以太网之类的数据链路层技术之间的映射关系,并且提出了子网带宽管理(Subnet
Bandwidth Management,SBM)的方案,它适用于802.1 LAN,如以太网、令牌环和FDDI等。SBM是数据链路层上的QoS,它通过将高层QoS映射到特定的数据链路层上实现在第二层上的快速交换。
SBM也是一个信令协议,它允许网络节点和交换机之间在SBM框架内进行通信和协调,并实现向高层QoS的映射。在SBM体系结构中,要求所有的数据帧必须通过至少一个SBM交换机。SBM的主要构件有三个部分:
请求模块(Request Module, RM):请求模块驻留在每个端系统中而不驻留在任何交换机中。请求模块根据管理员所定义的策略,将高层的QoS协议参数映射到第二层的优先级别。
带宽分配器(Bandwidth Allocator, BA):带宽分配器保存子网内资源的分配状态,并且根据可用资源的情况以及管理员所定义的策略来执行接入控制。
通信协议(Communication Protocols, CP):通信协议用于在SBM系统中,各个不同的组件之间进行通信。SBM体系结构提供了RM-to-BA以及BA-to-BA的信令机制来请求资源、改变或删除分配资源。
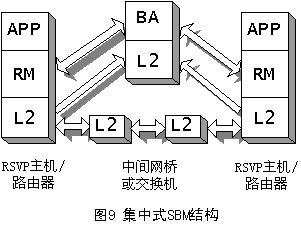
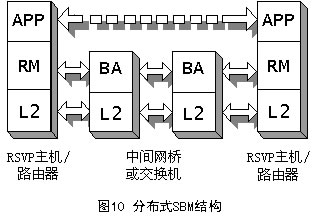
SBM有两种形式的体系结构:集中式结构和分布式结构,它取决于BA所处的位置,如图9和图10所示。不管在哪种形式的结构中,RM都必须在需要请求资源的端系统中。APP表示需要使用RM的应用,它可以是用户应用程序,也可以是高层协议(如RSVP)。
在集中式结构中,只有单个的BA来实现整个子网的带宽管理与分配,每个端系统中包含一个RM,而网桥和交换机中则不需要RM。当端系统需要请求资源时,则由它的RM首先向BA发出请求通信。在这种结构中,BA需要知道整个子网的拓扑结构。
在分布式结构中,子网内所有的网络设备中都需要实现BM功能,所有的端系统中仍然需要实现RM。在这种结构中,每个BA需要知道与它连接的本地网段(一个子网可能包括多个网段)的拓扑结构。
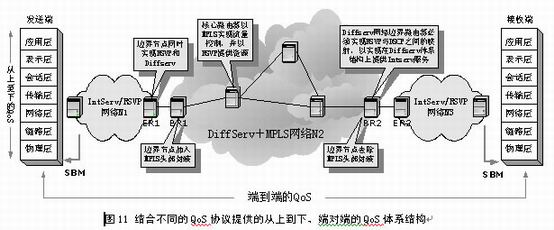
关于作者
姜明,计算机专业博士研究生。主要研究方向为网络体系结构、网络QoS。非常高兴能够与广大同行就IP QoS及IPv6协议方面的相关问题进行切磋,欢迎大家对本文多提宝贵意见,我的Email是:jiangmingcc@163.com。
下一代互联网关键技术IP QoS(2)
赛迪网
中国信息化(industry.ccidnet.com)
相关链接: